Creating a compiler for retro part 2: Working with the agent
Every time you start a project, there’s that spark that ignites something deep inside you. It usually fades as you move forward.
After creating that big waterfall list of tasks, I started using the Jules agent. I immediately noticed how painfully slow it was. At the time, Gemini 2.5 was the default for the 15 free tasks, but it had a nice feature: you could see the VM output and what the AI was trying to do, so you could step in and help guide it.
Before anyone starts pointing out what I could have done better, remember this: I was experimenting. I wanted to learn firsthand how to properly direct an agent. Every new model changes the way you need to interact with it, so I chose to stay in interactive mode instead of auto-planning—even after Gemini 2.5 was deprecated and Gemini 3 Flash became the default.
I struggled a lot — not just with the slow performance, but with the AI’s erratic behavior. Even with proper context, it would sometimes act unpredictably. It felt like it had multiple personalities: in its (now removed) “thinking” traces, it would contradict itself, produce bizarre code reviews, or create useless branches with zero changes.
To my surprise, Jules struggled with very simple and repetitive refactors. Sometimes it even complained that the task was too manual and asked if it could do something else instead. That got frustrating.
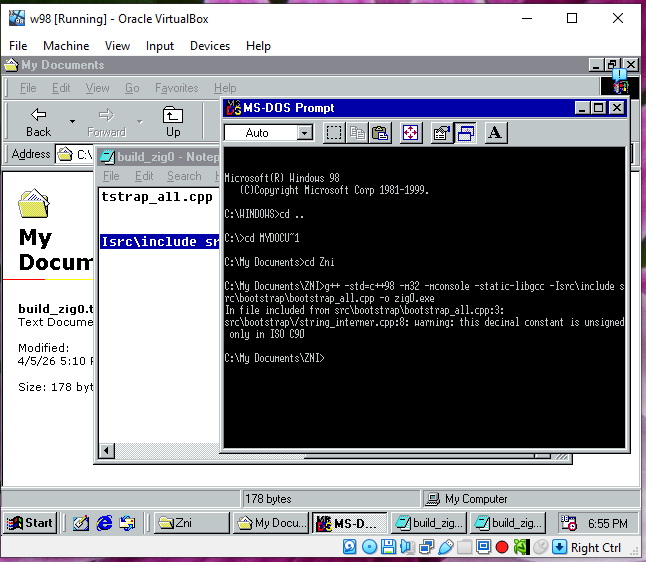
But realistically, I couldn’t complain too much. It was doing work I didn’t have time to do—writing C++98 code under tight constraints. And to its credit, it helped keep things consistent. Left on my own, I would have been tempted to use modern features instead of sticking to things like manual dynamic arrays.
At the start of each task, it always asked questions. Some felt like filler or basic confirmation, but others were surprisingly precise and forced me to think more carefully about the problem.
There were also some funny moments. For example, I once explained how to use git reset --hard, and it ended up in an infinite loop—making changes, resetting, and repeating: “I made a mistake, I need to start again.”
Refactoring in a growing codebase is unavoidable. If you trust an agent to handle it, be prepared to review everything carefully. Blind trust will burn you.
Another major pain point was the code review tool Jules used. When it worked, it was helpful. But when Jules failed to address it, it failed hard. Several times, after receiving a code review, the agent would lose context, reset its workspace, and commit “solutions” based on hallucinated changes without implementing the actual requested work. I had to restart tasks multiple times because of this.
One key lesson I learned was the importance of scope. The agent didn’t really improve by having more context in its "memories" it had a capability ceiling. To get good results, I had to narrow the scope aggressively or split tasks into much smaller pieces.
A good example was making the parser non-copyable again. I had experimented with a copyable parser for a while, which led to subtle and messy segmentation faults in C++ due to pointer arithmetic and type coercion issues. Fixing that required breaking the problem into many smaller tasks.
After a dozen failed attempts, I created a Markdown “guide” file to track refactors. I would define exactly what needed to be done, execute tasks one by one, mark them as complete, and repeat the process.
Running tests after each change is usually a good practice except when you expect massive regressions, like during architectural shifts (for example, when I introduced the AST lifter). In those cases, I had to be extremely explicit and keep tasks short. Otherwise, the AI would run the test suite, detect failures (which was expected), and then try to fix everything—never finishing because the system was intentionally unstable. That’s where I had to step in manually.
When it came to regression fixing, the AI could help—but its fixes were often just duct tape. Lots of duct tape. Eventually, I had to step back, review the whole system, and design proper fixes instead of patching symptoms.
And yes—there is still a lot of duct tape in the codebase. At some point, I had to stop accepting the “easy” solutions and push for proper implementations, even if that meant spending multiple tasks on a single change.
One advantage, though, was speed in experimentation. I could run parallel “spike” tasks—trying different approaches and comparing results. That helped identify cleaner solutions with fewer regressions. This is where having good tests really paid off.
For the core components (lexer, parser, type checker, and backend emitter), I relied heavily on TDD. I prefer writing accurate tests first rather than realizing later that a test wasn’t actually verifying anything useful. For example, I once failed to properly define how catch and orelse expressions should be evaluated (LHS vs RHS), and the issue went unnoticed until very late. Fixing it required updating tests and refactoring accordingly. The AI tried to “fix” the tests incorrectly a few times, but those mistakes were easy to catch.
As for hallucinations, most of them were caught either during code review or by tests. Since I was building foundational components with relatively few dependencies, the damage was usually contained.
Code repetition is definitely present. For example, the FNV-1a hash function appears multiple times in the codebase. Every time the AI needed hashing, it reimplemented it instead of reusing existing code. I still need to clean that up—but it’s not critical right now.
Will I continue using it? Maybe. It helped, but let’s be clear: it’s not magic. This wasn’t a case of writing “build a Zig compiler for Win98, no mistakes” and walking away. Not even close.
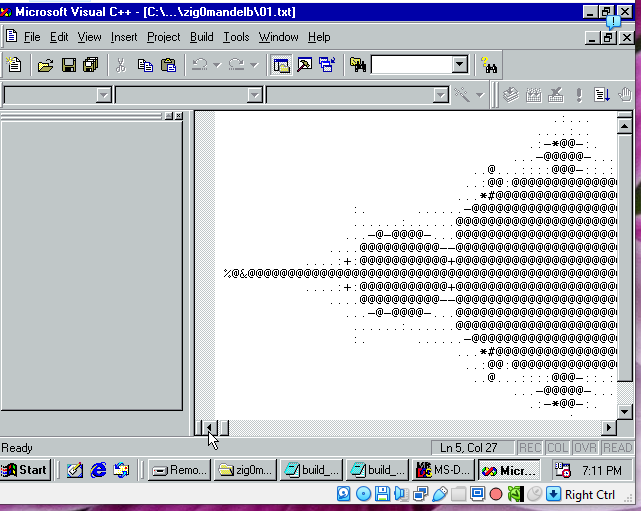
Was it worth it? Yes. My Windows 98 VM proves it.